我最近这样做 Vibe Coding:一次分享会里的工具、模型与工作流
最近我做了一个小 App:实时监听会议内容,再把它转成字幕和翻译。
这不是我熟悉的领域。我没有系统做过 macOS / iOS 开发,也没有完整的 UI 设计经验。但正因为这个项目,我第一次真正开始感受到什么叫 “vibe coding”。
它不是“什么都不懂,随便让 AI 写写看”。它更像是先抓住一个真实需求,然后用合适的工具、模型和工作流,把一个原本不会做的东西,快速推进到可运行、可验证、可迭代的状态。
这篇文章是我最近一次分享会的整理版。与其说它是教程,不如说是我这段时间反复验证下来最有用的几个判断。
先说结论:我现在最看重三个变量
如果你问我最近做 vibe coding 时最常想的是什么,不是 prompt,而是这三件事:
- 工具:你用网页聊天工具、云端 builder,还是本地 coding agent,决定了你的工作方式。
- 模型:不是选“最强”就够了,而是要知道什么场景该用什么模型。
- 需求:如果你自己都不知道要拿 AI 来做什么,那装再多工具也不会有产出。
我越来越确信,工具和模型不是背景板,它们会直接塑造你解决问题的方式。
1. 工具不是替代关系,而是分工关系
现在 AI 工具很多,但我会把它们粗暴地分成三类:
- 网页聊天工具:适合快速搜索、找引用、了解最近别人怎么做。
- 云端 builder:适合做 mockup、试视觉方向、生成一个大致可用的原型。
- 本地 coding agent:适合真正落地,因为它能读你的文件、调用本机命令、使用你的工程结构。
以前我会把这些工具混在一起讨论,现在不会了。现在我会先问自己:我到底是在“找信息”、在“试想法”,还是在“把东西做出来”。
如果我的目标是调研某个新方案,或者想知道别人最近怎么做某个技术问题,网页端会更顺手,因为它更擅长搜索和引用。如果我要快速试一个产品界面,云端 builder 很方便,因为任务发出去之后我不一定要守着电脑。但如果我真要把一个项目做完,我最后还是会回到本地 coding agent,因为只有这类工具能真正吃下完整上下文。
这也是我最近越来越明确的一点:工具决定工作方式。你手里拿的是“会聊天的网页”,还是“能读代码、改文件、跑命令的 agent”,最终能做出来的东西会完全不同。
2. 模型不要抽象地选“最强”,要按场景选
模型选择也是一样。我现在的习惯很简单:如果没有太多时间做细致横评,我会优先用头部模型,再结合公开榜单和官方 benchmark 做判断。
比如编程场景里,我会参考公开的代码能力排行榜,至少先知道目前哪些模型在 coding 任务上表现稳定。
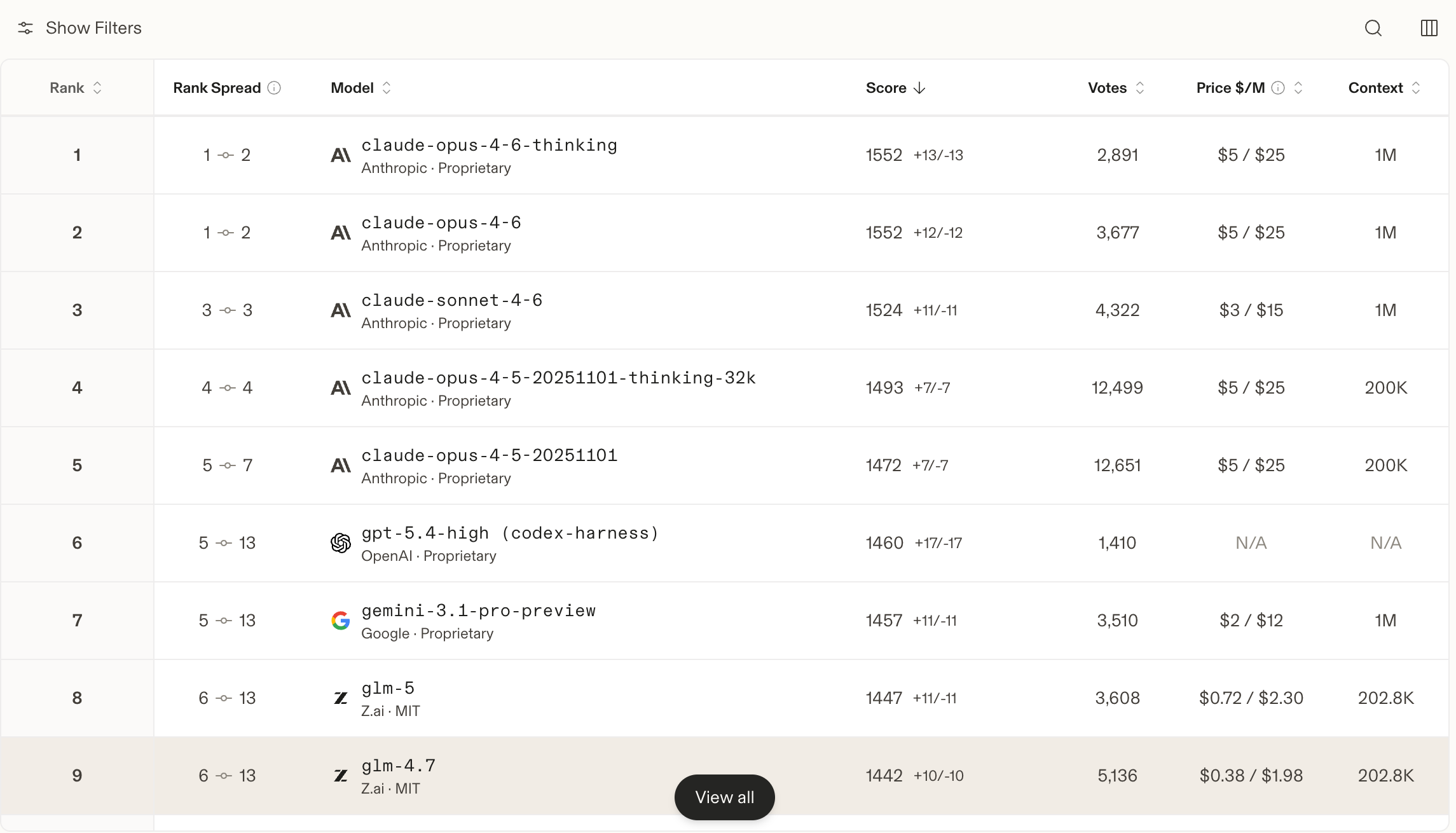
同样,像 CursorBench 这种官方评测,也可以帮助我快速建立一个直觉:哪些模型更适合长任务,哪些模型在多轮交互里更稳。
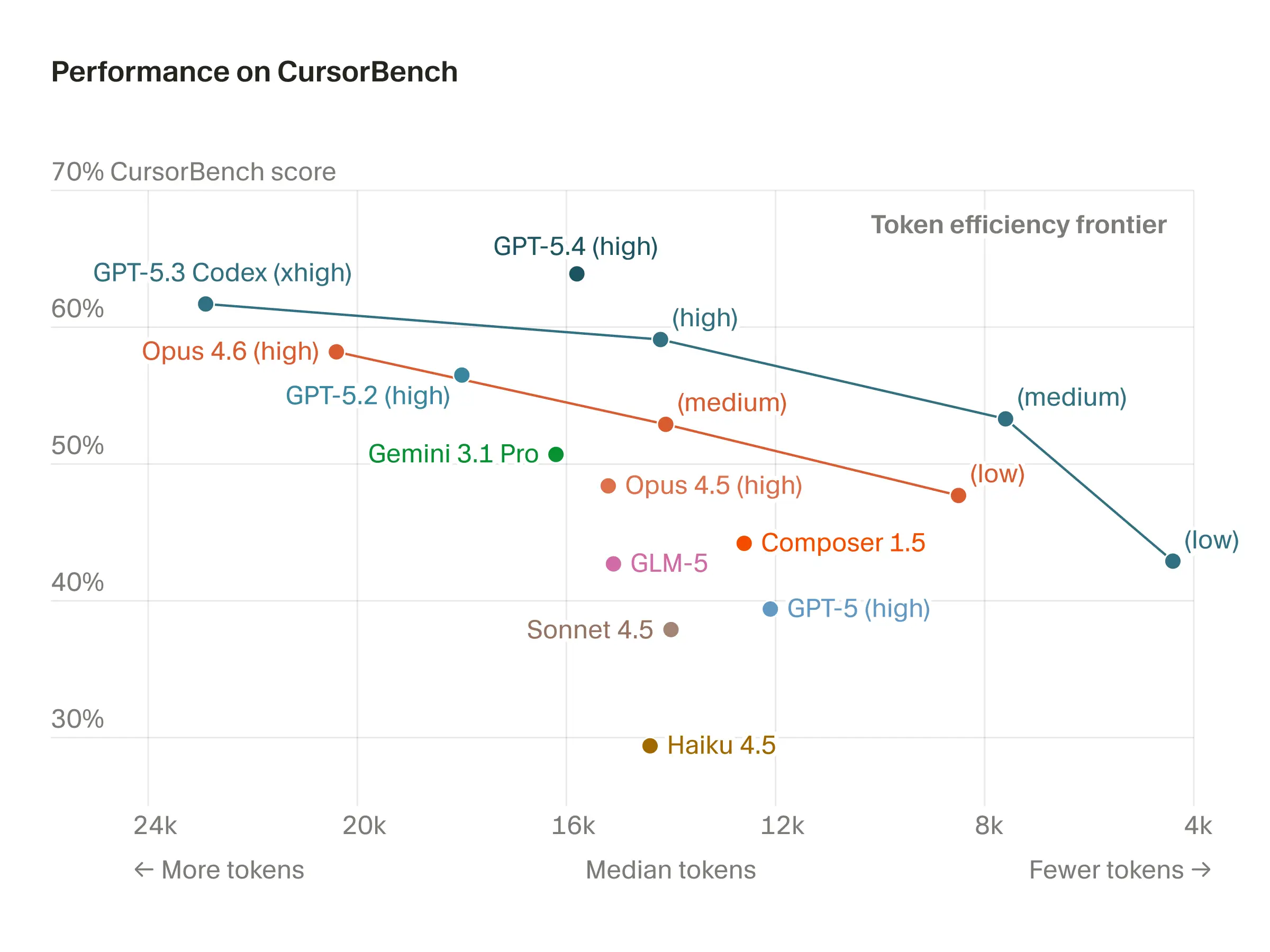
我现在尤其在意一个指标:多轮任务能力。
因为很多问题不是“一问一答”能解决的。你可能要让模型先读代码、再查资料、再改实现、再根据结果继续调整。如果一个模型第一轮很惊艳,但第二轮、第三轮就开始跑偏,那它在真实工作里并不好用。
所以我的经验不是“永远用同一个模型”,而是:
- 要快速找最近的资料和引用,优先选搜索能力强的工具和模型组合。
- 要做长期、多轮的 coding 任务,更看重稳定性和 multi-turn 表现。
- 没时间细测时,先用头部模型,别在冷门模型上花太多比较成本。
3. 成本下降,才让 vibe coding 真正开始
如果要我说最近半年最大的变化,我不会先说模型变强了,而是会说:成本下来了。
以前很多 coding agent 都是按次数或高额订阅计费。那时候我的习惯是尽量把任务合并,争取一次把事情讲清楚,因为每次调用都很贵。这样做的问题是,交互会变得很重,prompt 会越写越长,人也会越来越谨慎。
但当成本降到一个普通人可以放心试错的水平之后,整个使用方式就变了。
你会更愿意开新线程、更愿意让它重做、更愿意试一个不确定的方向。很多原本觉得“还是算了,别浪费额度”的尝试,现在都可以直接做。
我觉得这才是 vibe coding 真正开始普及的前提。不是因为大家忽然都变得更懂 AI 了,而是因为试错成本终于低到了足够低。
4. 真正稳定产出的,不是 prompt 花活,而是上下文和 workflow
很多人会把重点放在 prompt 技巧上,但我自己的体感是:想稳定做出东西,真正关键的是上下文和 workflow。
我们之前在团队里,为了让 AI 一两轮内就给出质量更高的结果,会先把需求写成 draft,再让大模型基于项目里的 rules、skills、代码和文档去整理成 final,最后再 review 这个 final,确认目录结构、数据结构和实现方向没问题,再进入生成代码的阶段。
这套方式跟我们在这份文档里总结的方法很接近:
它背后的核心逻辑其实很朴素:你给 AI 的相关信息越多,它越容易输出你真正想要的东西。
当然,现在我在做自己的探索项目时,没有以前那么强调每一步都要写得特别完整了。因为成本下降之后,很多事情可以边做边修。但即便如此,我还是会保留两个习惯:
- 开工前先把 workflow 讲清楚,比如先写 spec、再做实现、最后补 change log。
- 让 AI 尽量读取相关文档和代码,而不是只靠一段模糊需求自由发挥。
换句话说,vibe coding 不是放弃结构,而是把结构放在更轻量、但仍然有效的位置上。
5. 最近特别有用的三个具体技巧
5.1 用语音先把模糊想法倒出来
很多时候,真正卡住我的不是“不会写 prompt”,而是脑子里只有一个模糊想法,不知道怎么组织成文字。
这时候语音输入工具就特别有用。我最近很喜欢 Typeless ,因为它会把我口语里那些重复、停顿和不完整表达整理成更像命令的文本。
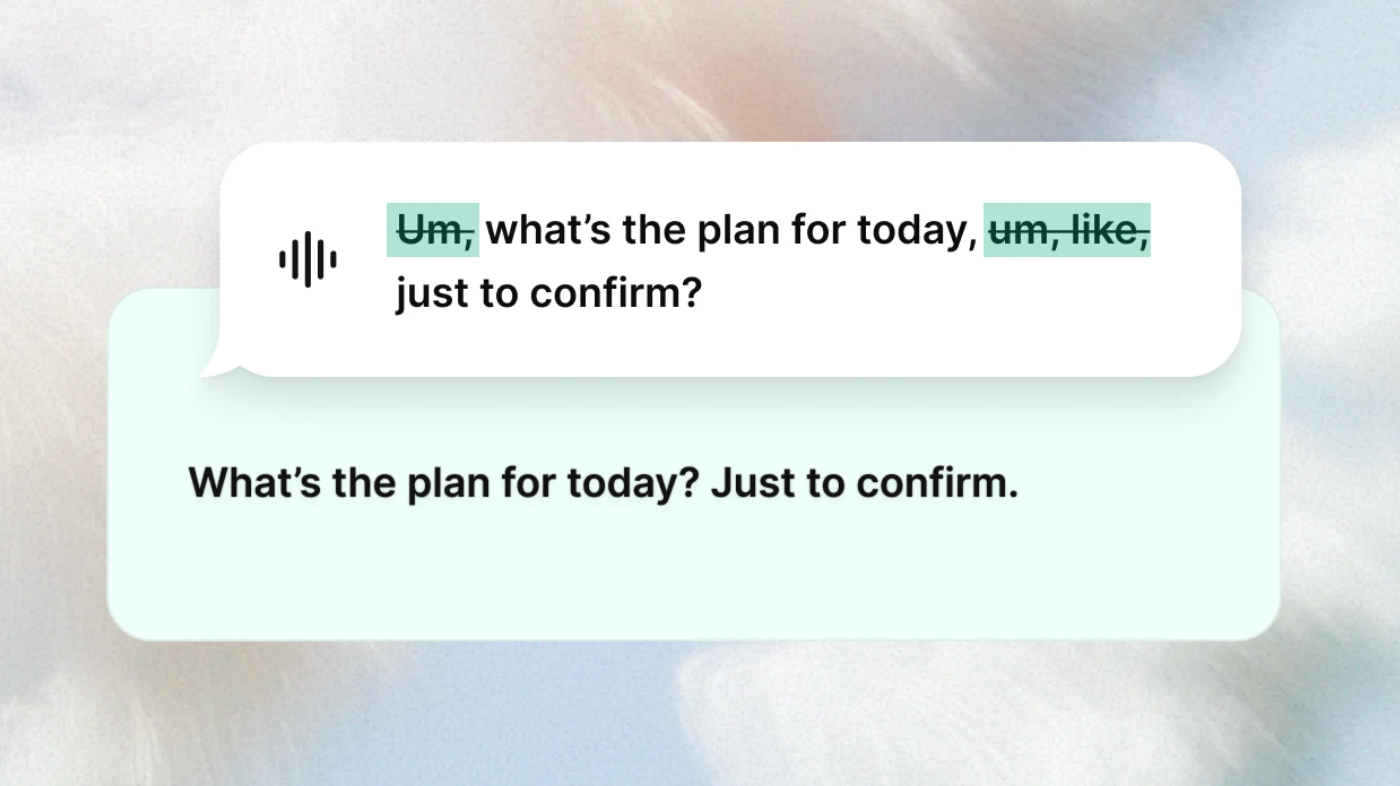
这件事看起来很小,但实际特别重要。因为 vibe coding 很依赖“快速迭代”,而语音能显著降低你把想法喂给 AI 的摩擦。
5.2 用 worktree 隔离任务,避免上下文互相污染
如果你开始让 AI 做稍微复杂一点的事情,很快就会遇到一个问题:上下文会互相污染。
比如我想同时对比几套技术方案,或者让 agent 分别去验证不同代码库里的能力,这些任务彼此相关,但又不应该共用同一个工作现场。否则上下文会越来越混乱,最后谁也说不清它当前到底在处理哪件事。
这时候 git worktree 很有价值。把不同任务拆到不同 worktree 里,等于给每个 agent 一个独立工作环境。这样它既能操作本地文件,又不会把多个实验揉成一团。
对我来说,这已经不只是 Git 技巧,而是 AI 协作时非常实用的环境隔离方式。
5.3 需要精准版式时,用代码生成图,不要直接赌生图模型
我最近还有一个很强的体感:只要图片里有明确文字、对齐、尺寸和组件结构,我会优先考虑“用代码画出来”,而不是直接丢给图片模型。
原因很简单。图片模型很擅长风格,但不擅长精准。尤其是宣传图、应用商店物料、带很多文字的界面图,它很容易在细节上出错,文字放大之后更明显。
所以我现在更常见的做法是:
- 先让图片模型给我一个风格方向。
- 如果风格是对的,再让 coding agent 用前端代码把它重做出来。
这样做的好处是,风格和精度可以拆开处理。前者交给图片模型找感觉,后者交给代码模型保证可控性。
6. 两个最近做出来的小东西
这些方法不是抽象总结,我最近确实拿它们做了两个自己用得上的项目。
第一个是 TransFlow 。它现在已经不只是一个代码仓库,而是一个我自己会持续使用和迭代的产品。
Mac 版官网在这里:transflow.cyron.space 。
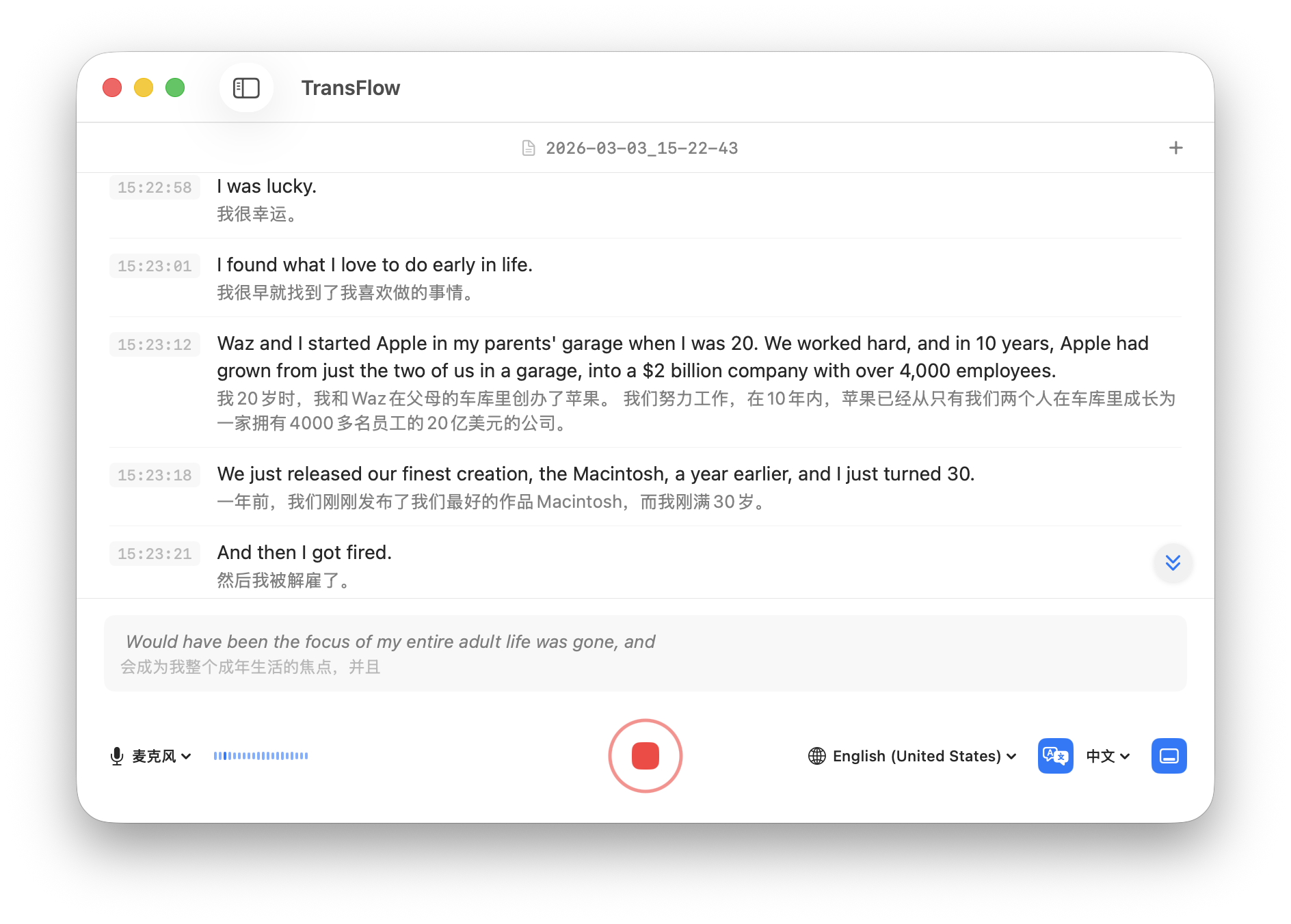
它最初是为了开会和面试时做实时字幕与翻译辅助。尤其是在英语会议、跨口音沟通,或者会后需要快速回顾内容的场景里,这类工具对我很有帮助。
从官网现在的版本来看,TransFlow 这条产品线已经比较清晰了:它基于 Apple Speech 做实时转录,结合 Apple Translation 做实时翻译,支持捕获其他 App 的音频,并且可以把内容导出成 SRT 或 Markdown。更重要的是,这套流程是偏 on-device 的,这对隐私和响应速度都很关键。
这里面对我最重要的启发不是“AI 能替我写完所有代码”,而是:即便你没有这个领域的经验,你也可以在 AI 的帮助下快速补齐到足够开工的程度。
iOS 版则叫 TransVoice。按我目前的进度,它还在审核中,但已经可以通过 TestFlight 提前试用。
这一版我更看重的点,是它开始从“实时转录与翻译”进一步走向“可整理、可复盘”的方向。比如宣传图里强调的:
- 多人发言自动区分
- 支持编辑文本
- 导出为 SRT / Markdown
这背后其实还是同一个思路:别只做“识别到了”,而是把后续整理、回看和再利用也一起考虑进去。
第二个是 markdown-downloader 。我做它的原因很现实:有些网站的正文和图片并不容易被 agent 直接读取,但如果先把内容下载下来,后续无论是整理资料、做引用,还是继续加工成文章,都会顺很多。
这其实也很符合我现在对 vibe coding 的理解:先把真实工作流里的阻塞点找出来,再给它做一个小工具,而不是先空想一个“很酷的 AI 产品”。
最后:Vibe Coding 不是不思考,而是更快地验证思考
如果我要把这次分享压缩成一句话,那就是:
vibe coding 不是减少思考,而是降低“把想法变成可运行结果”的成本。
我现在最推荐的做法也很简单:
- 从一个真实需求开始,不要从“我也想试试 AI”开始。
- 把工具按场景拆开,不要指望一个工具包打天下。
- 少迷信 prompt 技巧,多补上下文、多规定 workflow。
- 当成本已经足够低的时候,就多试、多开线程、多做小实验。
很多以前需要你先学很久、准备很久、犹豫很久的事情,现在其实已经可以先做起来了。
这也是我最近最强烈的感受:对于个人开发者来说,真正的门槛不再只是“会不会”,而是你愿不愿意开始把这些工具用进一个真实的问题里。